ご要望またはご協力できることがございましたらお気軽にお問い合わせください
一般的なお問い合わせと所在地情報
お問い合わせ
データ抽出機能を備えたBMCツール

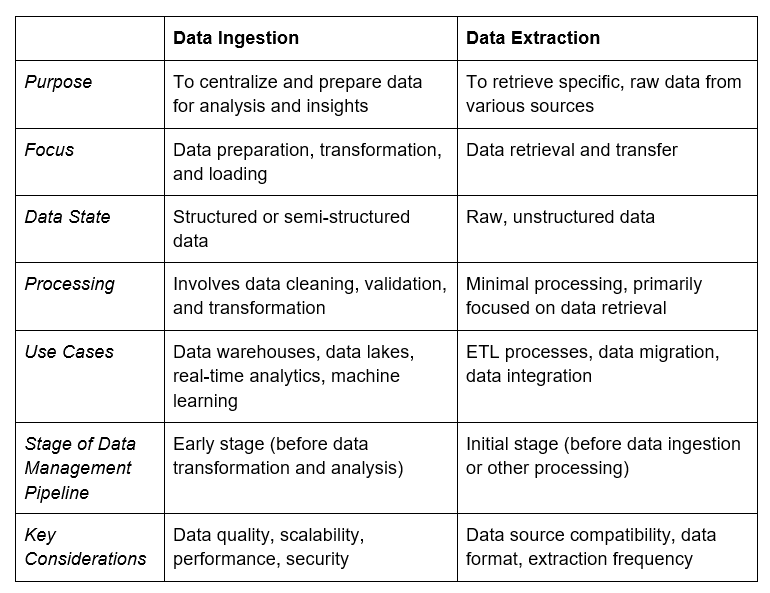
ビッグデータ抽出ツールの種類
ETLツール
データの抽出、変換、ロードを効率化し、効率性とデータ品質を向上させる自動化されたソリューション。
ETLツールを発見

バッチ処理ツール
効率的なツールは、大量のデータをスケジュールされたバッチで抽出し、リソースの利用を最適化し、システムへの影響を最小限に抑えます。
BMC AMIバッチオプティマイザを探る
オープンソースツール
技術的専門知識が必要なカスタマイズ可能でコスト効果の高いツールで、柔軟性とコミュニティサポートを提供します。
プロセス