ご要望またはご協力できることがございましたらお気軽にお問い合わせください
一般的なお問い合わせと所在地情報
お問い合わせ
DataOpsの説明
DataOpsが分析を活用して、実行可能なビジネスの洞察を推進する方法を理解する
DataOpsとは?
データ操作の略であるDataOpsは、データ管理の分野でアジャイルエンジニアリングとDevOpsのベストプラクティスを適用して、データをよりよく整理、分析、活用し、ビジネス価値を解放する実践です。これは、DevOpsチーム、データエンジニア、データサイエンティスト、分析チームの間のコラボレーションであり、データ駆動型ビジネスの洞察の収集と実装を加速します。
DataOpsの成功において中心となるのは、データパイプラインを 自動化およびオーケストレーション することです。手動の努力だけでは生成されるデータの量に追いつくことはできません。自動化とオーケストレーションにより:

さまざまなシステム間でのデータの迅速かつ効率的な移動

データパイプラインの健康とパフォーマンスの最適化
DataOpsの推進要因
多くの企業がデータを整理し、活用して価値を生み出すのに苦労しています。理由は以下の通りです:
 |
急速に増加するデータソース 新しいタイプのデータやより複雑なビジネスモデルによるもので、簡素化が困難です |
 |
不十分なコラボレーションとビジネスの関与 成功する文化的変革を促進することができません |
 |
成功を測定するためのアプローチが不明確 特に基盤となるイニシアチブにおいて、多くの利点が他のチームのパフォーマンスで観察されるためです |
 |
プロセスの不一致 従来のデータ管理プロセスと手法が新しい技術(例:人工知能(AI))とうまく一致しない場合 |
 |
スケールでの運用上の課題 新しい機能のスピード、柔軟性、適時性、カスタマイズに対するステークホルダーの期待が急速に高まっています |
DataOpsの目標
データを正しく使用することで、組織の運営方法を向上させ、革命的に変えることができます。しかし、残念ながら、データの88%が未分析のままです、 そして、ビッグデータプロジェクトのわずか15%が生産に至ります。 DataOpsは、チームがデータを共同作業し、どのようにアクションに展開するかを変えることで、これらの問題を解決することを目指しています。
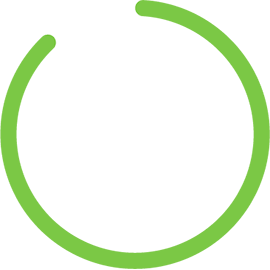
データの最大88%が未分析のままです
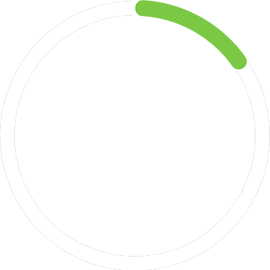
ビッグデータプロジェクトのわずか15%が生産に至ります
DataOpsの仕組み
DataOpsの核心は、質の高いデータを活用することです。企業がこれを成功裏に実現すると、チームとリーダーはより高い価値を提供し、現在および将来のリスクをより自信を持って管理できます。成功したDataOpsの取り組みには、次の要素が必要です。
自動化

コミュニケーションとコラボレーション

文化

自動化
コミュニケーションとコラボレーション
文化
BMCのDataOpsへのアプローチ
BMCでは、現代のビジネス環境がチームとリーダーに解決すべき課題と問題のリストを増やしていることを理解しています。データを活用することを学ぶことは、変化の激しい、破壊的な世界で進化し、競争力を保つために重要です。
データオーケストレーションの業界リーダーとして、私たちは企業が データ駆動型ビジネスになるための支援の豊富な歴史を持っています。私たちのソリューションは、クラウドからオンプレミスのデータセンター、エッジ、そしてその間のすべてを網羅する複雑な環境をサポートするように設計されています。
BMCはDataOpsにユニークな価値を提供します:
- データパイプライン のエンタープライズ規模のオーケストレーションを提供する
- あらゆるデータ技術やインフラストラクチャにわたって、エンドツーエンドの可視性と予測サービスレベル契約(SLA)を提供する
- 技術ユーザーにとってスムーズな体験を確保しながら、製品でガバナンスおよびコンプライアンスルールを強制する
Control-Mのようなポートフォリオソリューションを使用すると、最も複雑なデータパイプラインでさえ簡素化し、データサイエンティストがより良いワークフローを作成できるようにし、データを最大限に活用することができます。